Projects
Implementation of 3D Bounding Box Paper
After reading this fascinating paper discussing 3D bounding boxes from a single image, published by contributers from Zoox and George Mason University, I decided implementat the work using PyTorch (here).
The important aspect of the paper is that the 3D Bounding Box is to be constrained tightly by the 2D detection region which allows for a set of four 3D corners to lie on a side of the 2D box when projected onto the image. The result is a system of 16 equations using the regressed orientation and dimension allowing for the localization of the object to be solved for. As it is an over-constrained system of equations, SVD is used to solve for the set of corners that reduces the reprojection error.
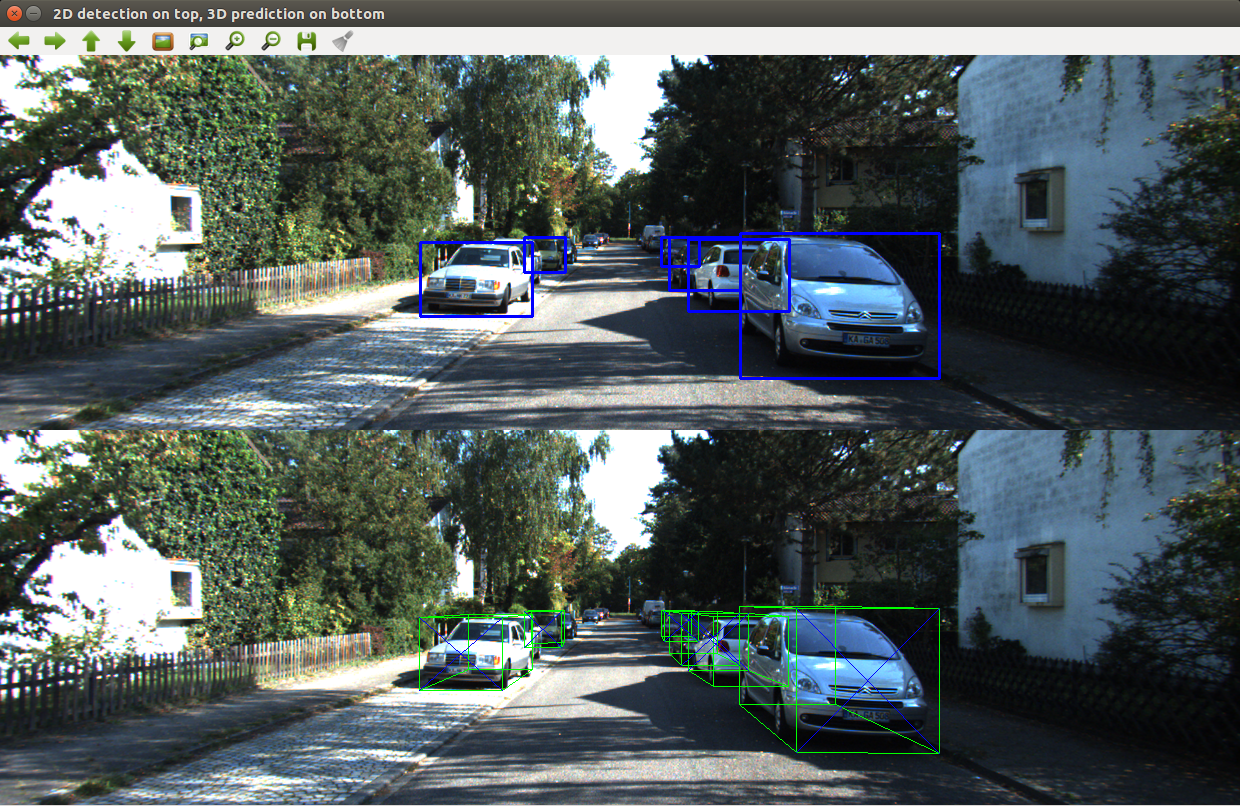
The top image shows the detection of cars using the YOLO neural network architecture trained on Pascal VOC. The cropped images of the car are then passed through a convolutional neural net trained on the KITTI dataset that produces a multibin orientation estimate and dimension estimation, which is used to solve for location, allowing for projection of the 3D box onto the image.

Here is the full pipeline running on a video, achieving a speed of around 0.4s per frame. The biggest bottleneck is the result of YOLO being run on the CPU, which is an improvement that can be implemented. Another improvement would be to employ some type of pose filtering in order to reduce the jittering of each pose and to create a visualization of the road with all the cars in it.
University of Colorado Robosub Software Lead

The RoboSub team at CU Boulder competes annually at the RoboSub Competition held in San Diego. This international competition is centered around creating an Autonomous Underwater Vehicle (AUV) to autonomously complete certain tasks.
As a relatively new team at the competiton, the software has been written from scratch, and improvements are made daily. It is exciting to test out new code, as almost everything is a first for our team.
As software lead, I have gained extensive experience with ROS (Robotic Operating System) in Python as well as C++. Since I have to understand the entire software stack, I have also gotten hands-on experience with robotics methods that are commonly used in industry. Some of the software tools that are employed include:
- Extended kalman filter to integrate DVL, IMU, and pressure sensor data to give absolute odometry
- PID control loop for movement
- Neural network using YOLO (You Only Look Once) to classify objects in images
- OpenCV to localize these objects in the global frame

Example of the output bounding boxes of the YOLO-based neural net. Any classified objects are then passed to OpenCV algorithims in order to detect known 2D points and use solvePnP (Perspective n Point) to obtain a 3D Pose of that object.
Some of the things I am currently working on for the sub:
- Building a map of previous objects seen to not be constrained by a linear progression of tasks
- Creating an accurate model of the sub to implement an LQR controls system
- More robust computer vision localization
FFDDCU (Freakin' Fast Drivable Data Collection Unit)
Freshmen Projects Final (Awarded Best Project in Section)

The FFDDCU was a very successful final project for an intro projects course. Features of the tank:
- Arduino reading pressure, temperature, and light
- Raspberry Pi taking in sensor information from Arduino
- Pi uploaded live video feed and sensor plots to a Web Server
- Motor commands sent to Pi from web, drivable from anywhere